$var =~ /pattern/; # Pattern match $var =~ m/pattern/; # same as above $var =~ s/pattern/replace/; # substitution $var =~ tr/chars/replace_chars/; # transliteration
my $s = "scatter";
if ($s =~ /cat/) { ... } # true if $s contains "cat"
if (/dog/) { ... } # true if $_ contains "dog"
=~'' is not assignment (``='').
my $pet = "ground hog";
if ($pet !~ /camel/) {
print "My pet is not a camel\n";
}
Remember comparison operators have equal (==) and not-equal (!=)?
#!/usr/bin/perl -w
$_ = "I Wish I Was a Mole In the Ground"; # using the special variable $_
# to simplify the comparison
print "Matched 1\n" if(/mole/); # no match
print "Matched 2\n" if(/e I/); # matches
print "Matched 3\n" if(/eI/); # no match
print "Matched 4\n" if(/Ground /); # no match
$s =~ s/cat/wea/; # Replace cat with weaNow
$s contains "sweater".
As usual, the substitution operator s/ / / operates on default
scalar variable $_ if $varName =~ part is omitted:
s/cat/wea/;
#!/usr/bin/perl -w my $seq = "ATTATGCGGCG"; print "DNA: $seq\n"; $seq =~ s/T/U/; print "RNA?: $seq\n"; $seq =~ s/T/U/g; print "RNA: $seq\n"; exit;
Global substitution. By default, s/ / / substitute only the first match. s/ / /g will change the behavior, and ALL instances which matches the pattern get substituted (g for global match).
Try the following:
my $story = "My,cat,ate,a,rat!"; print "Before: $story\n"; $story =~ tr/cr,/rc /; print "After: $story\n"; $story =~ tr/a-z/A-Z/; print "Capitalized: $story\n";
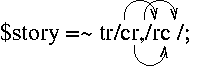
Useful when you want to take a string and replace every instance of some character with some new character.
Does the following s/ / /g do the same thing as the tr/cr,/rc / above?
my $story = "A,cat,ate,a,rat!"; print "$story\n"; $story =~ s/c/r/g; $story =~ s/r/c/g; $story =~ s/,/ /g; print "$story\n";
As long as your data file has some regularity, Perl can extract information out of it.
/h/Match: "home", "pocket gopher", "Horseshoe crab"
Dot matches ANY single character except new-line character
'\n'. This is the most frequently used pattern.
/a.e/
Matches: "ace", "pale ale", "made", "Mama eel"
/[abcde]/
Match: "hello", "doggy", "kool-aid"
Not Match: "HELLO", "soup"
/[0-9]/Matches any single digit: "456", "K9", "R2D2"
Other examples:
[0-9\-] # matches 0-9 or minus, note the backslash to escape
# the special meaning of - in [ ]
[a-z] # matches any single letter (lower case only)
[a-zA-Z0-9_] # matches any single letter both upper and lower casses,
# digit, or underscore
[^0-9] # match any single non-digit
[^ ] (caret, ^, immediately after the left bracket)
specifies a single character which is not in the list.
Note that a caret, ^, has another meaning in regular
expressions if it is NOT immediately after the left bracket.
Abbrev. Meaning equivalent to \d A digit [0-9] \w A word character [a-zA-Z0-9_] \s A space character [ \t\n\r\f] \D A non-digit [^0-9] \W A non-word char [^a-zA-Z0-9_] \S A non-space char [^ \t\n\r\f] # Perl 5.10 and newer \h A horizontal space [ \t\f] \v A vertical space [\n\r] \R A line break (End of Line)
my $diary = "I started to eat dinner at 17:50:21."; print "Found a time notation\n" if ($diary =~ /\d\d:\d\d:\d\d/);
\t"), new-line ("\n"), carriage return
("\r"; not often used in unix), and form feed ("\f")
not often used in unix).
\n Unix, new Mac
\r\n DOS, Windows
\r Old Mac
\R will automatically figure this out.
[\dA-Z] # a single upper case letter or digit
Question: What is the difference between the following two?
. vs [\d\D]
{ } [ ] ( ) ^ $ . | * + ? \
But you can match these characters by putting backslash character
('\') in front of it. This backslash is called escape
character. It is escaping from the special meaning of the
character following it.
$var = "2+2=4"; print "match 1\n" if ($var =~ /2+2/); # it does not match print "match 2\n" if ($var =~ /2\+2/); # matches $sam = "a lot of $ $ !"; print "Sam is rich\n" if ($sam =~ /lot of \$/); # matches
Matt dog and cat
Lee cat
Kent parrot
Naoki shrimp
Hayley dog
Mariana llama
You want to extract the line which contains dog OR cat OR llama. You can use alternation metacharacter |.
open (INFILE, "<pets.txt");
while(<INFILE>) {
print if (/cat|dog|llama/);
}
/(dog|cat)bert/
/(19|20)\d\d/
/[hm]ouse(|keeper|cat)/
/Hmm+/
Plus (+) means one or more of the immediately previous character.
a? match 'a' 0 or 1 times
a* match 'a' 0 or more times, i.e., any number of times
a+ match 'a' 1 or more times, i.e., at least once
a{n,m} match at least n times, but not more than m times.
a{n,} match at least n or more times
a{n} match exactly n times
* and +
/Hmm+/doesn't match "Hm" (need one more 'm').
/Hmm*/matches "Hm".
/pocket gophers?/
/\d+/
/[A-Za-z]+\s+\d*/
Example: Population estimates (July 1, 2005)
| Alabama | 4557808 |
| Alaska | 663661 |
| Arizona | 5939292 |
| Arkansas | 2779154 |
| California | 36132147 |
| Colorado | 4665177 |
/\d{2}|\d{4}/
while(<IN>) {
chomp;
print "Found bert in line $.\n" if (/bert/);
}
It will find ``dogbert'', too.
\A (^) means match at the beginning of the string
\z ($) means match at the end of the string
/\Abert/ # does not match "dogbert", but matches "bertram" /^bert/ /bert\z/ # does not match "bertram", but matches "dilbert" /bert$/ /\Abert\z/ # ONLY matches with exactly "bert" /^bert$/
Note that the caret (^) has a different meaning now, since the caret is
not immediately after left square bracket.
while(<IN>) {
chomp;
s/\A\s+//; # remove leading spaces
s/\s+\z//; # remove trailing spaces
print "Found bert in line $.\n" if (/\Abert\z/);
}
If a line contains leading spaces (" bert") or trailing spaces
("bert "), the pattern (/^bert$/) won't match the
line. This kind of problem happens frequently, so it is a good idea
to clean up these leading/trailing spaces with the substitutions.
Create a program, which reads in a file given in the command line argument and removes empty lines (i.e. print out the non-empty lines to the screen).
# extract hours, minutes, seconds
if ($time =~ /(\d{2}):(\d{2}):(\d{2})/) { # match hh:mm:ss format
$hours = $1;
$minutes = $2;
$seconds = $3;
}
# Extract the sequence name from the FASTA sequence name line
if (/^\s*>\s*(.+)\s*$/) {
$seqName = $1;
}
# extract hours, minutes, seconds
if ($time =~ /(((\d{2}):(\d{2})):(\d{2}))/) { # match hh:mm:ss format
$hms = $1;
$hm = $2
$hours = $3;
$minutes = $4;
$seconds = $5;
}
Just count the order of the opening parenthesis.
Instead of $1, $2, etc., you can use \1, 2, etc.
$_ = "abba";
if (/(.)\1/) {
print "Matched char: $1\n";
}
$_ = "ding dong";
if (/(.).(..) \1.\2/) {
print "$_ matched:$1:$2\n";
}
An example of sequence name:
>gi|49188826|gb|CO267808.1|CO267808 151H8 Opium poppy leaf cDNA library Papaver somniferum cDNA clone 151H8 5' similar to Unknown function, mRNA sequence
The accession number is red and italicized.
#!/usr/bin/perl -w
# shortenName.pl
# shorten the sequence names to accession numbers from fasta file.
while (<>){
chomp;
unless (/^>/) { # Not the name line
print "$_\n";
next;
}
# We are dealing with the name when the process reaches here.
s/^>\s*//; # get rid of '>'
my @line = split /\s+/;
my $first = shift (@line); # gi|49188826|gb|CO267808.1|CO267808
my @numbers = split /\|/, $first;
$accNum = $numbers[3];
$accNum =~ s/\.\d+$//; # remove version numbers
print ">$accNum\n";
}
exit;
#!/usr/bin/perl
while(<>) {
...
}
This is a short hand way of doing something similar to:
#!/usr/bin/perl
while (my $file = shift @ARGV) {
open (IN, "$file") || die "can't open $file\n";
while ($_ = <IN>) {
...
}
close (IN);
}
This kind of operations happens frequently (Parsing many files, line by line). Instead of writing out all of these, you can use while(<>){ }. This operator is as valuable as diamonds. Perl programmers love to be lazy!
#!/usr/bin/perl
# kitty.pl
while(<>) {
print $_;
}
If you do,
bash$ kitty.pl file1.txt file2.txt file3.txt > output.txt
the three files will be concatenated into one output.txt file. This
kitty.pl works like the unix command cat.
1 - I or V
2 - any
3 - D
4 - S
5 - G, A, or S
6 - G, A, S, or C
7 - G, A, S, or T
8 - G or A
9 - T
Extract the corresponding amino acid sequence from the following sequence.
> Rat AP
MILPFLVLAIGPCLTNSFVPEKEKDPSYWRQQAQETLKNALKLQKLNTNVAKNIIMFLGDGMGVSTVTAA
RILKGQLHHNTGEETRLEMDKFPFVALSKTYNTNAQVPDSAGTATAYLCGVKANEGTVGVSAATERTRCN
TTQGNEVTSILRWAKDAGKSVGIVTTTRVNHATPSAAYAHSADRDWYSDNEMRPEALSQGCKDIAYQLMH
NIKDIDVIMGGGRKYMYPKNRTDVEYELDEKARGTRLDGLDLISIWKSFKPRHKHSHYVWNRTELLALDP
SRVDYLLGLFEPGDMQYELNRNNLTDPSLSEMVEVALRILTKNPKGFFLLVEGGRIDHGHHEGKAKQALH
EAVEMDEAIGKAGTMTSQKDTLTVVTADHSHVFTFGGYTPRGNSIFGLAPMVSDTDKKPFTAILYGNGPG
YKVVDGERENVSMVDYAHNNYQAQSAVPLRHETHGGEDVAVFAKGPMAHLLHGVHEQNYIPHVMAYASCI
GANLDHCAWASSASSPSPGALLLPLALFPLRTLF
If you want to include all degenerate characters, here is IUPAC code for all degenerate bases.
| IUPAC code | Meaning |
| A | A |
| C | C |
| G | G |
| T | T |
| M | A or C |
| R | A or G |
| W | A or T |
| S | C or G |
| Y | C or T |
| K | G or T |
| V | A or C or G |
| H | A or C or T |
| D | A or G or T |
| B | C or G or T |
| N | G or A or T or C |