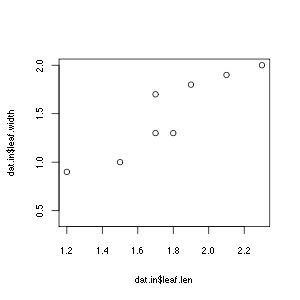
Let's say that we had grew 10 plants in shady and sunny environments, and measured the leaf lengths and width. You can use the data imported in the previous Exercise. If you didn't do the importing exercise, here is the converted text file.
dat.in <- read.table("data.txt", header=T, sep="\t")
names(dat.in) dim(dat.in) dat.in
plot(dat.in$leaf.len, dat.in$leaf.width)
cor(dat.in$leaf.width, dat.in$leaf.len, use="complete.obs")
boxplot(leaf.width ~ treatment, data=dat.in)
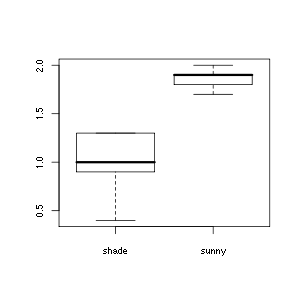
mean(dat.in[dat.in$treatment == 'shade', "leaf.width"]) mean(dat.in[dat.in$treatment == 'sunny', "leaf.width"])
anova.fit <- lm (leaf.width ~ treatment, data=dat.in) anova(anova.fit)Created anova table:
Analysis of Variance Table
Response: leaf.width
Df Sum Sq Mean Sq F value Pr(>F)
treatment 1 1.936 1.936 25.813 0.0009523 ***
Residuals 8 0.600 0.075
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Slightly differnt wayt to look at the fit of linear model.
summary(anova.fit)
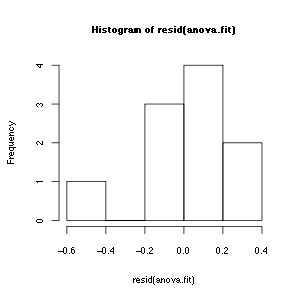
Looking at the distribution of residuals:
hist(resid(anova.fit))